그리고 이를 통해 교차판매(Cross selling), 묶음판매, 부정행위 적발 등에서 사용할 수 있다.
이번 포스팅에서는 support, confidence, lift 활용법과 Apriori 알고리즘에 대해서 포스팅하며 실제로 어떻게 사용할 수 있을지 간단한 예를 들어 설명하도록 한다.
먼저 연관규칙생성 시 사용할 수 있는 결정도구는 3가지로 정리할 수 있다.
1. support(지지도)
2. confidence(신뢰도)
3. lift(향상도)
실제로는 위의 3가지를 섞어서 사용해도되고 하나만 사용해도되지만 반드시 데이터를 관찰해가며 적당한 도구와 최소 수치를 정할 수 있도록 해야한다.
Apriori Algorithm은 support를 활용하여 Assosiation Rule를 구하는데 알고리즘 설명에 앞서 연관규칙생성에 사용할 수 있는 도구의 의미를 알아보자.
먼저 support는 지지도로서 정의는 다음과 같고 이는 사건 A가 일어날 확률로 표현된다.
이는 frequent item sets을 판별하는데 사용이 된다.

예를 들어서 A와 B의 support를 구하기 위해서는 (A와 B가 동시에 발생한 사건 수)/(전체 사건 수)가 된다.
다음은 confidence는 신뢰도로서 다음과 같이 정의할 수 있다. 이는 사건 A가 주어졌을 때 B사건이 일어날 조건부 확률로 표현되며 아이템 집합 간의 연관성 강도를 측정하는데 사용된다. 쉽게 풀어보면 사건 A가 일어났을 때 사건 B도 함께 일어난 확률이라고 볼 수 있다.

예를 들어서 A와 B의 confidence를 구하기 위해서는 (A와 B가 동시에 발생할 확률)/(A가 일어난 확률)가 되고 이는 A가 발생했을 때 이 중에서 B가 얼마나 발생할지를 나타낸다.
아무래도 전체중에 A, B가 동시에 발생할 확률보다는 더 연관도가 높다고 할 수 있다. 하지만 수식에서 보는 것과 같이 A를 구매했을 때 B를 구매하는 것과 B를 구매했을 때 A를 구매하는 것은 다를 수 있어서 선후행 관계를 파악할 수 있다.
그리고 실제로 효용가치가 있는지 판별하기 위해 사용하는 lift는 향상도로서 조건절과 결과절이 서로 독립일 때와 비교하여 두 사건이 얼마나 함께 발생하는지를 나타낸 확률이다.

이는 실제 발생확률을 각 사건의 발생이 독립일 경우에 비해 그 사건이 동시에 발생할 예상기대 확률로 나눈 것을 뜻하며 수식을 정리하면 (A가 발생하고 B가 발생할 확률)/(B가 발생할 확률)로 나타낼 수 있다.
여기서 lift = 1 이면 조건절(Antecedent)과 결과절(Consequent)은 서로 독립이고 lift > 1 인 경우 서로 양의 상관관계로서 서로 연관이 있다고 판단할 수 있으며 lift < 1 인 경우는 음의 상관관계로서 연관이 없다고 판단할 수 있다. 하지만 이는 반드시 데이터를 보고 판단해야하며 lift < 1 인 경우가 무조건 틀리다고 볼 수 없다.
이제 Apriori Algorithm의 예시를 보도록 하자.
여기서는 frequent item sets을 고르기 위해 support를 사용했다.
다음과 같이 원천 데이터가 있다고 가정하자.
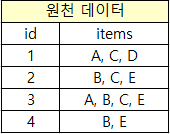
id는 구매자(또는 트랜잭션, 주문)이고, items는 상품셋이다.
최소 조건을 support > 1로 가정했다. (확률이나 경우의 수나 같다.)
전체 구매 상품중에 A 2번, B 3번, C 3번, D 1번, E 4번이 등장했고 D는 support > 1에 의해 제거한다.
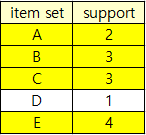
남은 A, B, C, E로 조합을 만들어보면 다음과 같이 나타낼 수 있으며 발생 횟수(support)는 다음과 같다.

여기에서도 마찬가지로 {A, B}, {A, E}가 제거되며 남은 A, B, C, E로 조합을 만들면 {A, B, C}, {A, B, E}, {A, C, E}, {B, C, E} 4가지가 나오는데 직전 단계에서 {A, B}와 {A, E}가 제거되었기 때문에 볼 필요가 없이 {A, B, C}, {A, B, E}, {A, C, E}, {B, C, E} 중에 {B, C, E}만 남게 된다.

이를 제거하는 이유는 {A, B, C}가 나올 확률이 아무리 커봤자 {A, B}가 나올 확률보다 작거나 같기 때문이다. 이를 초월 집합 제거라고 부르며 수준 미달의 초월집합을 제거함으로써 효율적인 계산을 할 수 있게 된다.
이 결과가 의미하는 것은 B, C, E가 빈발 항목 집합, 즉 frequent item sets라는 것이다.
한번 쉽게 생각해보자.
만약 실제로 적용할 때에는 A를 구매했을 때 B를 추천하거나 C를 추천하는 경우가 많기 때문에 frequent item sets의 조합 크기를 2로 생각하고 {A, C}, {B, C}, {B, E}, {C, E}를 추천셋으로 만들어놓고 support 값으로 정렬, lift로 2차 정렬을 하여 상품셋 추천을 구현해도 되지않을까 싶다.
개인적으로는 상품셋의 퀄리티 보다는 상품셋의 규모가 매출에 더 큰 영향을 준다고 생각하기 때문이다. 물론 일정 수준 이상의 성능(퀄리티)이 나오는 경우에 한해서이다.
그럼 support, confidence, lift를 모두 활용한 예를 들어보도록 하자.
다음과 같은 구매내역을 가정한다. 최소 support는 0.35로 가정했다.


단일항목 집합으로 보면 다음과 같이 support 값을 구할 수 있다.
최소 support에 의해 D와 E는 제거된다.

2개항목 집합으로 보면 다음과 같다.
결국 최소 support에 의해 {A, B}와 {B, C}만 남게된다.

이는 단순히 support로 frequent item sets을 구한 것이다.
이번엔 confidence(신뢰도)를 고려해보자. 최소 신뢰도는 0.75로 가정한다.

min confidence 0.75에 의해 A=>B이 제거되었다.
이는 A를 구매했을 때 B를 구매하는 것보다 B를 구매했을 때 A를 구매할 확률이 높다는 것이고 C를 구매했을 땐 A를 구매할 확률이 100%라는 것을 의미한다.
이번엔 lift를 고려해보자. confidence를 support로 나눠주면 된다. 즉 support와 confidence만 알면 lift는 어렵지 않게 구할 수 있다.

lift > 1이 양의상관관계이므로 0.9를 제거하면 lift 1.5짜리 두 세트가 남게된다.
B=>C 는 support 0.5, confidence 1.0, lift 1.5 이다.
C=>B 는 support 0.5, confidence 0.75, lift 1.5 이다.
특히 B=>C의 경우 support 0.5에 의해 B와 C를 동시에 구매한 사람은 절반이고, confidence 1.0에 의해 B를 구매한 사람들은 C도 100% 구매한 것이다. 또한 lift 1.5에 의해 B를 구매했을 때 C를 구매할 확률은 단순히 C를 구매했을때의 확률보다 1.5배나 높아진다.
확실한 것은 현업에 적용하기 위해서는 도메인 지식을 잘 활용하는 것과 데이터를 관찰해가며 사용해야한다는 것이다. 도메인 지식을 잘 활용한다는 것은 데이터 클린징 또는 전처리를 잘 해야한다는 것과 같은 의미로 받아들였으면 좋겠다.
-
다음 포스팅은 FP-Growth에 대해서 포스팅해볼까 한다.
FP-Growth는 FP-Tree구조를 활용해서 Apriori algorithm의 연산속도 문제를 개선한 알고리즘이다. 확실히 Apriori 알고리즘은 구현하기 쉽지만 연산속도가 문제인 것 같다. 실제로 비슷한 것을 프로시저(쿼리)로 짠 것을 적용해달라고 해서 검증하다보니 연산속도가 장난이 아니어서 2step으로 나누어 일배치+월배치로 타협을 본 적이 있다.




댓글 없음:
댓글 쓰기