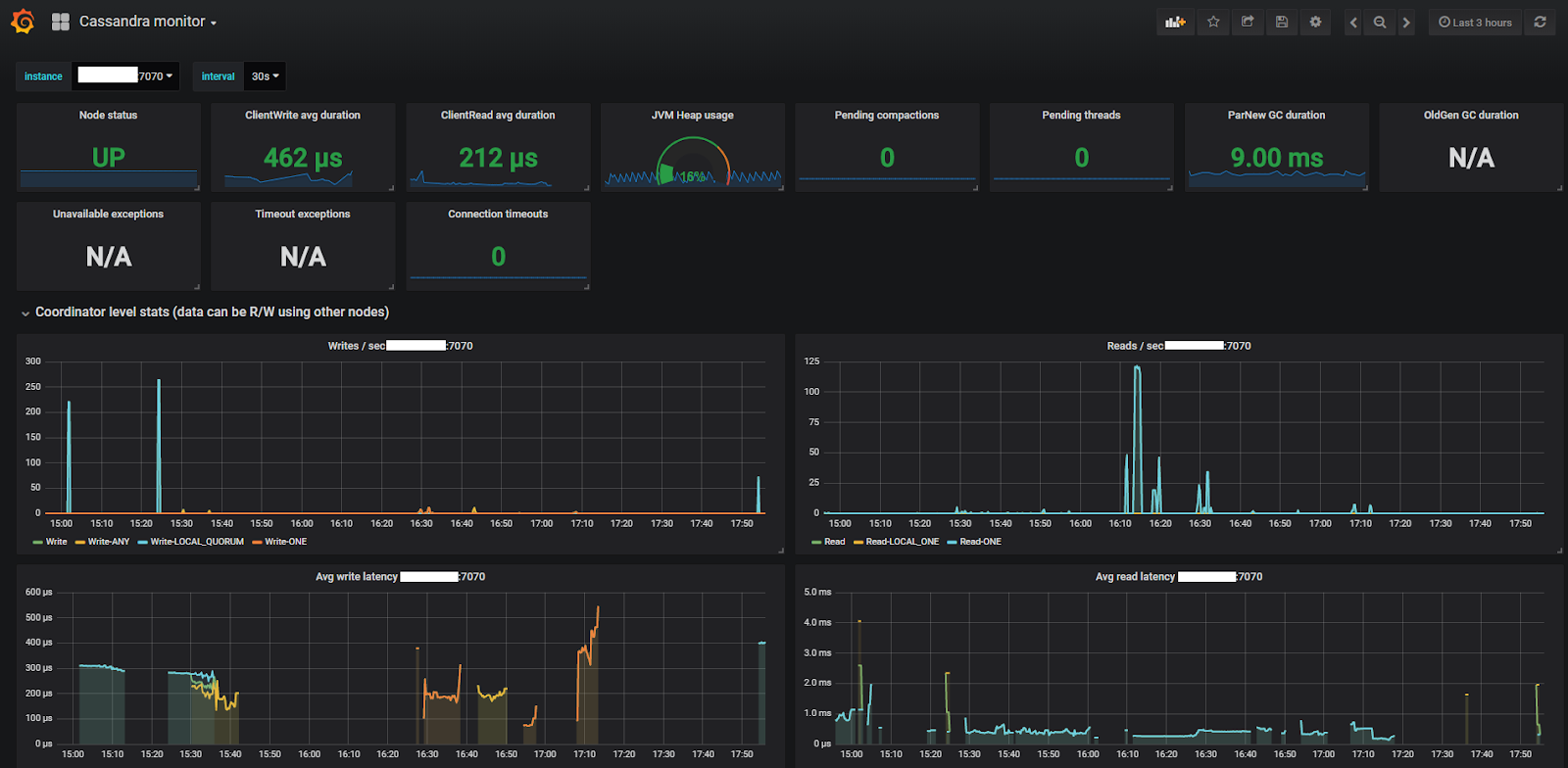
카산드라를 도입하기 위해서 스트레스 테스트를 해야할 때 카산드라 자체에서 지원하는 tool을 활용하면 쉽게 테스트가 가능하다.
본 포스팅은 카산드라 테스트 툴을 활용하여 가비지 컬렉터가 어떻게 동작하는지, 그리고 성능은 어떤지 보고자 한다.
gc는 서버의 메모리 스펙에 따라서 heap을 잘 조절해가며 최적화를 진행한다.
3대의 cassandra를 준비하고 각각의 GC 세팅을 다르게하여 테스트를 해보자.
서버 각각의 메모리는 32G이다.
그리고 java는 1.8(zulu jdk)를 썼고 zing test시에도 zing 1.8 version을 사용하였다.
후에 v11로 올려서 테스트해볼 예정이다.
테스트 하기전에 GC에 대해서 대략적으로 알아보자.
대부분의 객체는 life cycle이 짧다. 즉 객체는 빨리 소멸한다는 것이고 이런 객체들이 차지하고 있는 메모리를 잘 반환(청소)해야 할 것이다.
메모리에 객체가 할당되고 제거될 때에는 각각의 객체 size도 다르고 소멸주기도 다르기 때문에 결국 메모리 파편화가 발생하며 이는 새로운 객체가 할당될 때 문제가 된다. 마치 DB에서도 빈번한 insert/delete가 발생하면 인덱스에 페이지(블럭)의 순서가 꼬여서 단편화가 생기는 것과 같은 개념이다.
따라서 메모리 공간을 적절히 잘 나눌수만 있다면 그리고 그 메모리 공간 전체를 비울 수만 있다면 특별한 액션을 취하지 않아도 이 자체만으로 성능이 좋을 것이라는 추측이 가능하다.
하지만 GC가 발생할 때에는 Stop the world가 일어나서 어플리케이션이 잠깐동안 중단이 된다. 따라서 어플리케이션에 영향을 주지 않고 메모리가 full나지 않도록 하는 것이 목적이다.
객체와 GC 관계
1. 새롭게 생성된 객체는 Young generation의 eden에서 생성이 된다.
2. eden이 꽉차면 minor gc가 발생하고 이때 살아남은 친구들을 survivor1에 복사한다. 그리고 eden을 clear 한다.
3. 다음 eden에서 minor gc가 발생하면 survivor2에 복사하고 이때 survivor1에서 살아남은 친구들도 survivor2에 복사한다. 그리고 eden과 survivor2를 clear한다.
4. 이런 과정을 반복하면서 Young Gen에서 살아남은 친구들이 결국 Old Generation으로 복사가 된다.
즉 Young Generation(세부적으로 eden, survivor1, survivor2)과 Old Generation으로 나뉘는데 Young gen에서 발생하는 gc를 monir, Old gen에서 발생하는 gc를 full gc라고 부른다.
GC 종류마다 부르는 명칭은 다를지라도 청소하는 영역이 같다. (아래의 그래프에서 설명)
또한 suv1, suv2를 from, to 라고 불리기도 한다.
테스트할 GC는 CMS, G1GC 그리고 상용 GC인 ZING이다. ZING은 trial version으로 진행하였다.
테스트 하기전 설정을 살펴본다.
먼저 권장사항은 다음과 같다. 참고만하자.
출처 : Configuraing java heap space for cassandra

CMS 기준으로 설명해보면..
32G 시스템이므로 1/4크기만큼 주면 8G를 주기로 하였다.
MAX_HEAP_SIZE="8G"
HEAP_NEWSIZE="2G"
그리고 아래는 테스트 해가면서 조절해야한다.
-XX:NewRatio=2
-XX:SurvivorRatio=6
-XX:CMSInitiatingOccupancyFraction=75
위의 세팅을 해석해보자.
heap size가 8G인데 -XX:NewRatio=2이다. 즉 young:old 비율이 1:2이다. 만약 설정을 안하면 1:9가 default다.
young:old가 1:2이므로 8G를 배분하면 young이 약 2.6G, old가 5.3G을 가져간다.
-XX:CMSInitiatingOccupancyFraction=75이므로 75%가 찼을 때 GC 준비를 한다. 누군가 경험상으로 68%가 안전하다고 하는 글을 본적이 있지만 75%로 하였다.
XX:SurvivorRatio=6이므로 eden, suv1, suv2의 비율은 6:1:1이다. 따라서 young의 2.6G를 분배하면 1.95 : 0.325 : 0.325 가 된다.
G1GC나 ZING은 default 상태이다.
이제 본격적인 테스트를 해보자.
테스트 전 미리 원할한 jmx connection을 위해 아래와 같이 설정하였다.
authenticator: AllowAllAuthenticator
authorizer: AllowAllAuthorizer
CMS GC mixed read/write test
./cassandra-stress mixed ratio\(write=1,read=1\) duration=100m -rate threads=\32 -node ip


concurrentmarksweep가 full gc라고 보면 되고 parnew가 minor gc라고 본다.
oncurrentmarksweep가 약 21회 호출되었고 used heap size가 약 6G가 넘을 때 호출되었다. 다행히 max heap size까지 차지는 않았다. 하지만 일부 gc 그래프에서 튀는 것을 확인할 수 있다.
G1GC mixed read/write test
./cassandra-stress mixed ratio\(write=1,read=1\) duration=100m -rate threads=\32 -node ip


G1 Old generation이 full gc이다. 약 15회 발생했다.
7G 근처에서 발생했고 튀지는 않지만 조금 더 다이나믹하게 gc가 일어난다.
ZING GC mixed read/write test
./cassandra-stress mixed ratio\(write=1,read=1\) duration=100m -rate threads=\32 -node ip


아무래도 ZING의 경우 상용 GC라서 더 좋긴 할텐데 그래프가 궁금했었다.
테스트 해본 결과 원하는 결과(ZING의 성능)가 막 높게 나오지 않아서 원인을 찾는 중이고.. 메모리를 더 주고 테스트를 해봐야할 것같다. 아무래도 메모리 관리 측면에서 봐야할 것 같다.
-> 추후 대용량 배치+과도한 트래픽으로 인해 장애가 났었는데 당시 ZING의 위엄(?)을 느낄 수 있었다. disk가 밀리고, network traffic이 밀리는 상황에도 카산드라 노드들은 zing을 통해 메모리 관리를 매우 잘하고 안정적인 상태를 보여주었다.
그런데 카산드라가 죽었을때 메모리 반환을 빨리 안할까봐 메모리를 쿼터만 주고 했는데 다음 테스트에서는 많이 줘봐야겠다.
현재 mixed 방식(write/read)를 테스트 했는데 각각의 경우에는 추후 포스팅에서 테스트 결과를 공유하도록 하겠다.
ZING의 메모리를 더 늘리고, 버전도 UP 시켜서 각각 테스트해볼 예정이다.
ZING을 테스트하면서 하나 느낀점은 cassandra가 죽었을 때, 혹은 재부팅할 때 메모리 반환을 바로 하지 않는다. 무언가 설정이 있을 것으로 보이지만 프로세스를 죽여도 zing이 기존에 잡고 있던 heap memory를 바로 반환하지 않는 것이 발견되었고 이는 장애가 났을 때 바로 어플리케이션을 살려야할 경우 메모리가 부족해서 안살아날 가능성이 있기 때문에 max heap memory size를 잘 조절 해야할것으로 보인다.
그런데 카산드라가 죽었을때 메모리 반환을 빨리 안할까봐 메모리를 쿼터만 주고 했는데 다음 테스트에서는 많이 줘봐야겠다.
현재 mixed 방식(write/read)를 테스트 했는데 각각의 경우에는 추후 포스팅에서 테스트 결과를 공유하도록 하겠다.
ZING의 메모리를 더 늘리고, 버전도 UP 시켜서 각각 테스트해볼 예정이다.
ZING을 테스트하면서 하나 느낀점은 cassandra가 죽었을 때, 혹은 재부팅할 때 메모리 반환을 바로 하지 않는다. 무언가 설정이 있을 것으로 보이지만 프로세스를 죽여도 zing이 기존에 잡고 있던 heap memory를 바로 반환하지 않는 것이 발견되었고 이는 장애가 났을 때 바로 어플리케이션을 살려야할 경우 메모리가 부족해서 안살아날 가능성이 있기 때문에 max heap memory size를 잘 조절 해야할것으로 보인다.