가령 다음과 같은 상황이다.
Hadoop에 Parquet Format으로 떨궈진 데이터를 MSSQL에서 CREATE EXTERNAL TABLE 하는 경우에 아래와 같은 에러들이 발생할 수 있다.
1. java.lang.Integer cannot be cast to java.lang.Long

이 경우에는 int로 선언되어야 하는데 bigint로 선언된 경우이다.
따라서 bigint -> int로 바꿔주자.
2. java.lang.Long cannot be cast to java.lang.Integer

이 경우에는 bigint로 선언되어야 하는데 int로 선언된 경우이다.
따라서 int -> bigint로 바꿔주자.
3. java.lang.Double cannot be cast to parquet.io.api.Binary
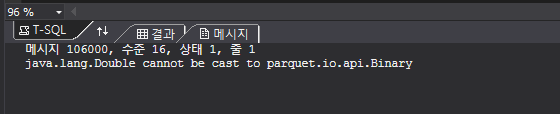
이 경우에는 float로 선언되어야 하는데 decimal(a,b)로 선언된 경우이다.
따라서 decimal(a,b) -> float로 바꿔주자.
4. java.lang.Double cannot be cast to java.lang.Integer
이 경우에는 float로 선언되어야 하는데 int로 선언된 경우이다.
따라서 int -> float로 바꿔주자.
따라서 int -> float로 바꿔주자.
이 외에도 Arithmetic overflow error converting tinyint to data type TINYINT. 식의 에러가 뜰 때에는 int가 맞는 타입인데 tinyint로 선언된 경우이다. 즉 tinyint -> int로 바꿔주자.

사실 윗 부분까지는 근본적인 해결책이 아니다. 일일이 컬럼에 경우의 수를 대입해서 풀지 않기 위해서는 하둡에 떨궈진 데이터의 스키마를 보고 즉시 해결할 수 있다.
제플린에서 df.printSchema()를 통해 dataframe의 스키마를 다음처럼 찍어볼 수 있다.
root
|-- col1: integer (nullable = true)
|-- col2: long (nullable = true)
|-- col3: long (nullable = true)
|-- col4: double (nullable = true)
|-- col5: double (nullable = true)
|-- col6: double (nullable = true)
|-- col7: integer (nullable = true)
|-- col8: string (nullable = true)
즉 이런 경우에는 다음처럼 생성하면 된다.
-- integer -> int
-- long -> bigint
-- double-> float
-- string -> varchar
SELECT * FROM TEST_TBL ;
데이터 타입이 잘 맞았다면 조회가 잘 될 것이고 그렇지 않다면 위에서 언급한 에러들이 출력될 것이다.
-
정리를 하면 먼저 하둡에 내린 데이터의 스키마를 알아낸 뒤에 테이블을 만들고 그게 여의치 않다면 에러를 보고 찾아낼 수 있어야 한다. 필자의 경우에는 후자였는데 먼저 해결하고 난 뒤에 근본적인 문제를 찾다보니 결국 스키마를 알아야겠더라.
즉 이런 경우에는 다음처럼 생성하면 된다.
-- integer -> int
-- long -> bigint
-- double-> float
-- string -> varchar
CREATE EXTERNAL TABLE TEST_TBL (
[col1] int NULL,
[col2] bigint NULL,
[col3] bigint NULL,
[col4] float NULL,
[col5] float NULL,
[col6] float NULL,
[col7] int NULL,
[col8] varchar(50) NULL
)
WITH (LOCATION='/user/hello/world/map/seoul/gangnam/201906',
DATA_SOURCE = HDFS_DS,
FILE_FORMAT = HDFS_FF_PARQUET,
REJECT_TYPE = PERCENTAGE,
REJECT_SAMPLE_VALUE = 10000,
REJECT_VALUE = 0.1
)
SELECT * FROM TEST_TBL ;
데이터 타입이 잘 맞았다면 조회가 잘 될 것이고 그렇지 않다면 위에서 언급한 에러들이 출력될 것이다.
-
정리를 하면 먼저 하둡에 내린 데이터의 스키마를 알아낸 뒤에 테이블을 만들고 그게 여의치 않다면 에러를 보고 찾아낼 수 있어야 한다. 필자의 경우에는 후자였는데 먼저 해결하고 난 뒤에 근본적인 문제를 찾다보니 결국 스키마를 알아야겠더라.




댓글 없음:
댓글 쓰기