먼저 오류 메세지는 다음과 같다.
Open Database Connectivity (ODBC) error occurred. SQLExecute returned error while inserting row 1
Open Database Connectivity (ODBC) error occurred. state: 'HY000'. Native Error Code: 0. [Devart][ODBC][PostgreSQL]character with byte sequence 0xc3 0x80 in encoding "UHC" has no equivalent in encoding "UTF8"
SSIS Error Code DTS_E_PROCESSINPUTFAILED. The ProcessInput method on component "ODBC Destination" (2) failed with error code 0x80004005 while processing input "ODBC Destination Input" (13). The identified component returned an error from the ProcessInput method. The error is specific to the component, but the error is fatal and will cause the Data Flow task to stop running. There may be error messages posted before this with more information about the failure.
The attempt to add a row to the Data Flow task buffer failed with error code 0xC0047020.
SSIS Error Code DTS_E_PRIMEOUTPUTFAILED. The PrimeOutput method on OLE DB Source returned error code 0xC02020C4. The component returned a failure code when the pipeline engine called PrimeOutput(). The meaning of the failure code is defined by the component, but the error is fatal and the pipeline stopped executing. There may be error messages posted before this with more information about the failure.
즉 UHC를 UTF8로 변환을 못해서 에러가 난다는 것 같다.
문제의 컬럼은 SRCHWD이며 일부 데이터가 Encoding 되어 생성되기 때문에 발생한 문제로 보인다.
결국 Postgresql에 넣을 땐 UTF8(포스팅 상황)로 변환해서 넣어야하는데 어떤 특정 데이터의 바이트 레벨에서 인코딩이 안되도록 문제를 발생시키는 것 같다.
이를 해결하는 방법을 제시할 것이다.
먼저 소스(MSSQL)와 타겟(Postgresql) 테이블 스키마는 다음과 같다.
- MSSQL

- postgresql도 스키마는 거의 동일.
하지만 SHOW SERVER_ENCODING로 서버 인코딩을 확인해보면 server_encoding은 UTF8로 되어 있다.

필자는 Devart ODBC for postgresql를 쓰고 있고 일반 ODBC보다는 빠르다.
이렇게 하면 다음과 같은 에러가 난다.
Open Database Connectivity (ODBC) error occurred. state: 'HY000'. Native Error Code: 0. [Devart][ODBC][PostgreSQL]character with byte sequence 0xc3 0x80 in encoding "UHC" has no equivalent in encoding "UTF8"
데이터가 워낙 많아서 확실히 어떤 데이터가 문제인지 찾을 수는 없었지만 추측하기로는 다음처럼 인코딩이 된 데이터가 문제가 된 것으로 보인다.
"%EC%8A%A4%EB%85%B8%EC%9A%B0%EB%9D%BC%EC%9D%B8+%ED%83%80%ED%94%84+%ED%92%80%EC%8A%A4%ED%81%AC%EB%A6%B0" 이런식으로 인코딩 된 데이터가 문제가 된 것으로 보이며 https://encoder.mattiasgeniar.be/index.php 사이트를 통해 확인을 해보면
RAW URL decoded
스노우라인+타프+풀스크린
으로 풀린다.
이런 데이터로 인해 문제가 되는 경우 두가지 해결 방법이 있다.
1. 원천 그대로 넣기
2. URL Decoding을 해서 넣기
이번 포스팅에서는 두 방법 모두 방법을 제시한다.
먼저 1. 원천 그대로 넣기 방법이다.

소스에서 읽어서 Derived Column으로 컬럼을 한번 Convert 해준 뒤에 Destination에 넣어주면 된다.
먼저 소스쪽을 보자.

소스 쪽에서 그대로 읽으면 CodePage가 949로 읽힌다. 이를 Derived Column으로 컬럼을 수정해준다.
필자의 경우에는 Expression에 (DT_WSTR,500)SRCHWD을 넣어주고 Data Type은 Unicode string [DT_WSTR]로 바꿔주었다.

마지막으로 Destination 부분이다.

DefaultCodePage를 65001 (UTF8)로 바꿔주고 BindCharColumnsAS를 Unicode로 바꿔주었다.
그럼 성공할 것이다!!
다음으로 2. URL Decoding을 해서 넣기 이다
최종 모양은 다음과 같다.
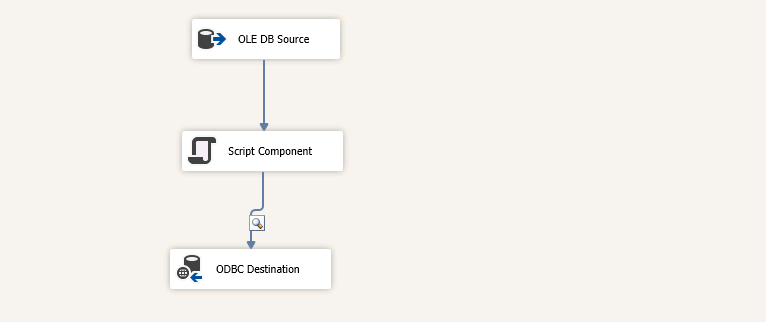
중간에 Script Component를 활용해서 URL Decoding을 해주기로 한다.

먼저 소스쪽이다. DefaultCodePage는 949이지만 AlwaysUseDefaultCodePage가 False이다.
이런식으로 하니까 CodePage를 1252로 읽는 것을 확인할 수 있었다. 1번 방법에서도 마찬가지로 1252로 읽을 것이다.

Codepage는 1252, DataType은 string [DT_STR]로 하였다.
이제 Script Component를 더블클릭해서 Edit Script...에 들어가서 C# 상태에서 URL Decode를 해주자.
References에서 System.Web을 추가해주었다.
그리고 상단에서 using System.Data; using System.Web;를 추가했다.

UrlDecode + UTF8로 변환하여 srchwddec에 담아서 반환한다.
/*
* Add your code here
*/
string str = HttpUtility.UrlDecode(Row.SRCHWD);
byte[] e = System.Text.Encoding.UTF8.GetBytes(str);
Row.srchwddec = System.Text.Encoding.UTF8.GetString(e);

마지막으로 Destination에서 Ansi, 949로 넣고 Column Mappings에서 새로 만든 컬럼을 Mapping 해주면 된다. 그럼 성공한다.
Open Database Connectivity (ODBC) error occurred. state: 'HY000'. Native Error Code: 0. [Devart][ODBC][PostgreSQL]character with byte sequence 0xc3 0x80 in encoding "UHC" has no equivalent in encoding "UTF8"
본 포스팅에서는 위와 같은 문제를 해결하기 위해 두 가지 방법을 제시하였다.
검색해보니 Postgresql에 데이터를 붓기란 굉장히 까다로운 작업임을 깨달았다.
1번은 원천을 살려서 적재하는 방법이고 2번은 원천을 가공해서 적재하는 방법이다.
필요에 따라서 알맞는 방법을 선택해서 사용하면 될 것이다.





















