(참고로 이번 편에서는 후자를 기준으로 포스팅을 하려고 한다.)
공공기관 지도 api를 사용하면 일단 간단하지만 장애나 점검 등에 대해서 그 기관에 의존성을 둘 수 밖에 없고 불러온 좌표 데이터를 그대로 사용해야 한다는 단점이 있다. 불러온 좌표 데이터를 합성하거나 수정할 경우 그때그때 화면에서 해줘야하기 때문에 아무래도 속도에 이슈가 있기 때문이다. 따라서 이러한 단점을 제거하기 위해 좌표 데이터를 미리 DB에 저장해놓고 이를 미리 합성해두는 방법을 사용할 수 있다.
크게 작업 순서는 다음과 같다.
1. 폴리곤을 정보를 구하고
2. MSSQL에 올리고
3. MSSQL내에서 폴리곤 합성/수정하기
먼저 우편번호별 폴리곤은 행안부에서 제공하고 있다.
http://www.juso.go.kr/addrlink/addressBuildDevNew.do?menu=bsin

우편번호로 활용되고 있는 전국 기초구역번호 정보를 전자지도(SHAPE)형식으로 제공한다고 되어있고 1년에 한번 업데이트를 하고 있으므로 데이터 시점에 대한 보정은 따로 고려해주어야 한다.
데이터의 형식은 다음과 같다. 활용가이드를 다운받으면 볼 수 있는 문서를 캡쳐했다.

201712기초구역DB_전체분.zip를 다운받아보면 약 70메가 정도 되는데 압축을 풀어보면 다음과 같이 17개로 나뉘어져 있고 각각의 폴더에는 .dbf, .shp, .shx 파일이 존재한다.

이 파일을 이제 Qgis라는 프로그램을 활용해서 열어보자.

서울특별시 파일만 열었으며 속성 데이터를 보면 다음과 같이 공간에 대한 정보를 볼 수 있다.
참고로 한글이 깨지는 경우 속성->소스->데이터소스 인코딩을 System으로 바꿔주면 정상적으로 볼 수 있다.

이제 이 벡터 정보를 Geojson 형태로 저장한다.

이렇게 저장한 11.geojson 파일을 열어보면 다음과 같은 구조로 되어있다.

우편번호별 폴리곤을 구하는 것이 목적이나 시도와 시군구까지 제공해주므로 이 데이터도 들고가자. 따라서 CTP_KOR_NM(시도명), SIG_KOR_NM(시군구명), BAS_ID(우편번호), geometry(타입과 좌표)를 사용하면 될 것이며 이제 json 형식의 파일을 db에서 제공해주는 기능을 활용해서 직접 엑세스를 하거나 그 방법을 사용할 수 없으면 직접 코드를 짜서 업로드하기 편하게 파싱해주도록 하자.
코드는 다음과 같다.
전체 코드는 드라이브에 올려놓았다.
드라이브 주소 :
https://drive.google.com/open?id=11UXBF06V3Q1_sZiDVTr8mGfDBZO5t-Lq

실행시 no module named 'shapely' 이라는 메시지가 나와서 직접 설치를 해주었으며
https://pypi.org/project/Shapely/에서 직접 모듈 whl파일을 다운받아서 설치하였다.
https://www.lfd.uci.edu/~gohlke/pythonlibs/#shapely
필자는 파이썬 3.7 버전이며 Shapely‑1.6.4.post1‑cp37‑cp37m‑win_amd64.whl를 설치하였고 드라이브에 올려놓았다.
코드를 돌려보면 서울만 실행했을 때 5667개의 우편번호가 존재했다.

아래는 결과 파일이며 이 파일을 이제 db에 업로드 할 것이다.

DB에 업로드 할 때 유의할 점은 COORD 컬럼을 텍스트 스트림(VARCHAR MAX)로 넣어주는 것이 중요하다.

최종 업로드 하면 위와 같은 화면이 된다.
테스트용으로 한번 폴리곤을 합성해보자.
SELECT CODE
, CTP_KOR_NM
, SIG_KOR_NM
, geometry::UnionAggregate(COORD).ToString() AS POLYGON
, geometry::UnionAggregate(COORD) AS WKT
FROM TESTDB..KOREA_GEOMETRY
GROUP BY CODE
, CTP_KOR_NM
, SIG_KOR_NM
코드, 시도, 시군구로 GROUP BY하여 폴리곤을 합성하고 geometry::UnionAggregate을 사용하면 ssms에서 바로 합성 결과를 다음처럼 확인할 수 있다.

합성 결과는 총 25개였다. POLYGON 컬럼이 최종적으로 합성된 결과이다.

서울특별시 기준으로 group by 결과가 25개이기 때문에 지도 객체도 25개가 출력되었고 폴리곤끼리 합성이다보니 폴리곤 내에 선 등 깔끔하지 못한 것은 mssql 내에서 제공하는 reduce나 buffer 함수를 사용하면 훨씬 깔끔하게 줄어들 수 있다.
필자도 여러가지 시도를 해보았고 지도를 최대한 간단하게(?)하기 위해 reduce 값을 높게 주면 생각보다 시간이 오래걸려서 적당한 타협점을 찾아야한다.
마지막으로 GEOMETRY 형식의 데이터를 화면에서 사용하기 쉽도록 JSON 형태로 저장해놓기로 하자.
GEOMETRY를 JSON으로 CONVERT하는 FUNCTION은 Hasan Savran BLOG를 참조하였고 드라이브에 저장해놓았다.

- hasan savran 님 감사합니다.
최종 결과는 다음과 같다.
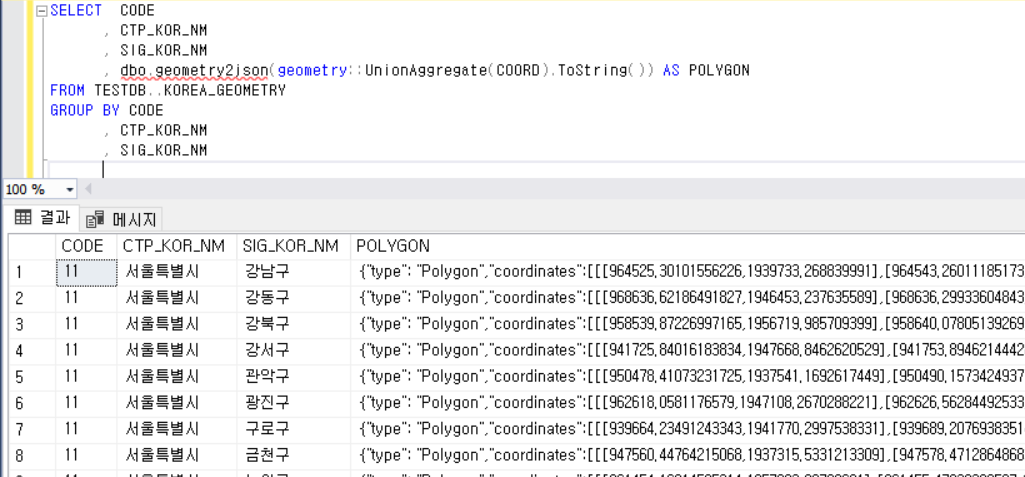
지금은 의미없이(?) 시도, 시군구 기준으로 GROUP BY를 했지만 사실은 원하는 우편번호 끼리 지역을 묶어서 사용해야 의미있는 결과가 나올 것이다. 대한민국 배송은 우편번호 기준으로 이루어지기 때문이다.
이제 이 폴리곤 정보를 SGIS등에서 제공하는 api나 솔루션(highcharts)을 활용하여 그릴 수 있고 폴리곤 데이터를 직접 들고있기 때문에 api 제공 기관에 종속성이 없을 뿐만 아니라 속도 측면에서도 훨씬 우월한 성능을 낼 수 있다.





























