디스크 용량이 약 4테라이고 해당 디스크는 db file만 존재하여 딱히 지울 파일이 없었다.
그래서 db 자체적으로 용량을 확보하는 방법밖에 없었다.
크게 궁금했던 부분은 다음과 같다.
1. mssql table truncate를 했을 때 바로 db size(.ndf, .mdf)가 줄어드는가?
2. shrink를 한다면 어떻게 진행해야 하는가?
1. table truncate 직후 db size(.ndf, .mdf)가 줄어드는가?
먼저 1번의 경우에 과연 mssql에서 table을 truncate를 했을 때 바로 DB FILE SIZE가 줄어들어 공간을 확보할 수 있을까? 작업 전 예측하기로는 이미 늘어난 상태의 DB가 쪼그라들(축소)것 같지는 않았다. 그래서 테스트를 해봤다.먼저 테스트용 DB를 생성했다.

초기 사이즈는 약 8MB, 증분은 64MB씩 되도록 하였다.
현재 깡통 DB이기 때문에 테스트 데이터를 밀어넣고자 랜덤데이터를 생성하였다.
증분 쿼리는 msdb에 sys.objects끼리 3번이상 cross join을 하면 DISK 공간이 부족해서 다음과 적당히 UNION ALL 해서 생성하였다.
ROW 18,819,504건, SIZE 2.54 GB 짜리 TABLE이고 DB FILE SIZE는 약 2.57GB가 되었다.

1번 궁금증이었던 mssql table truncate를 했을 때 바로 db size(.ndf, .mdf)가 줄어드는가?
는 해결되었다.
그럼 비할당된 공간은 어떻게 반환할 수 있을까?
DBCC SHRINKDATABASE 혹은 DBCC SHRINKFILE을 통해 비할당 공간을 줄여줄 수 있다.

반환 후 exec sp_spaceused 호출한 결과이다.
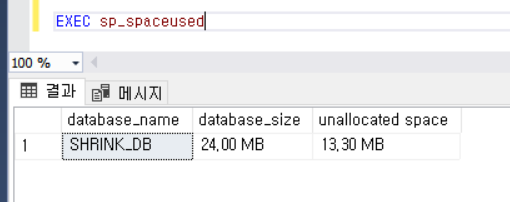
실제 DB file size도 줄어든 것을 확인할 수 있다.
2. shrink를 한다면 어떻게 진행해야 하는가?
사실 위의 경우에는 shrink를 해도 문제없는 DB였지만 실제 운영중에는 사용할 일이 없는 것이 좋다. 가장 큰 이유는 언제 끝날지 모르는 일이기 때문이다.실제 운영 db에는 수백~수천개의 table이 존재하고 이들에게 insert/delete 등이 빈번하게 발생할 수 있기 때문에 물리적인 조각화(Fragment)가 생길 수 있다.
조각화는 DBCC SHRINKDATABASE 혹은 DBCC SHRINKFILE를 사용하여 없앨 수 있는데 굳이 SHRINKDATABASE를 하여 db 전체의 조각화를 없애기에는 부담이 가기때문에 file별로 shrinkfile을 해주는 것이 좋다.
shrink를 할 때 online? offline? singlemode?
1. 찾아보면 대부분이 offline을 권장했지만 결론은 온라인으로 진행했다. 이유는 rollback이 필요없기때문에 cancel이 바로되고 루프를 돌며 조금씩 파일 size를 줄였기때문이다.
즉 DBCC SHRINKFILE (N'SHRINK_DB' , 0)가 아닌 DBCC SHRINKFILE (N'SHRINK_DB' , 타겟사이즈)를 계속 줄여가는 방법을 택했다.
아래와 같은 방법으로 진행했다.

필자의 경우엔 온라인 상태에서 진행을 했었고 전체 DB SIZE는 약 3.5TB이고 Disk 공간부족으로 약 600GB를 확보하였다. loop를 한번 돌때마다 1GB씩 줄이는데 1분이 걸릴때도 있고 15분이 걸릴때도 있는데 약 24시간에 300회 정도 loop를 돌았다. 즉 600GB를 확보하는데 48시간이 걸렸는데 이건 사용자에 따라 다르겠지만 언제 끝날지 모른다는 것을 꼭 알아둬야한다.
한가지 조금 걱정스러웠던 것은 온라인 상태에서 진행을 할때 클러스터드 INDEX도 물리적인 저장공간을 옮겨서 저장할 것같은데 이런 경우 운영중인 DB에서 쿼리가 INDEX를 잘 타는지, 아니면 INDEX도 옮겨지는 도중이라서 random I/O가 일어나는지 궁금하다. 후자라면 위험해보인다.